Automated End-to-End Encrypted Curator Backups for Massively-Scaled Elasticsearch via Puppet, AWS and Rsyslog
December 28, 2018
elasticsearch curator aws puppet rsyslog elasticsearch watcher![]()
Motivation
The main motivation for my writing of this article is because as of 2018 I was unable to find any internet resource that lays out a conceptual approach for automating, and alerting on, Elasticsearch Curator-based backups. The pieces are around, but nothing is complete and significantly less so for more legacy Puppet versions. However, in the interest of transparency and courtesy, I’d recommend that anyone implementing automated curator backups consider porting the logic I lay out ahead to an orchestrator like Ansible or Terraform because these tools are written for modern SRE and infrastructure engineering paradigms such as immutable infrastructure and security automation.
Requirements
Puppet 3 though it will work on all other versions with minimal tweaking
CentOS 7 (it was also tested on 6; needs very minimal tweaking)
tested on Elasticsearch 5 & 6
Elasticsearch Puppet module versions 5 & 6
Rsyslog rsyslog-8.24.0-16.el7.x86_64.rpm (which we are going to patch!)
Caveats
This is an expansive project so only non-trivial programmatic blocks and ideas are discussed. Configuring Curator or its required snapshots.yml file, in general, but also as it pertains to authenticating Curator to Elasticsearch over TLS, is not covered because an HTTPS elasticsearch cluster is not required for E2E Encrypted Curator backups, the ensuring of which is the specific topic of this tut. That being said the method used for Curator-to-cluster and intracluster authorization is assigning the Puppet master root cert and puppet agent client certs and private keys to any and all Elasticsearch and Curator configuration values named (something like) cert, client_cert and private_key, respectively. Shout out to Alan Evans for originally implementing this highly native approach: it works like a charm and I will be writing a brief post on it in the near future.
Ensuring full server-side encryption within S3 is a copy/paste/change-one-thing job so only a link to the needed S3 bucket policy is provided. Deleting old snapshots in S3 is similarly abbreivated. Ideally, S3 bucket creation and administration would be part of the Puppet automation process, but they are not because Puppet Forge’s AWS module offerings are limited relative to both the massive scope of AWS functionality in general, e.g. the Puppetlabs AWS module doesn’t include Lambda which isn’t related to this project, but is a core AWS service, and more specifically its S3 resource can assign a bucket policy, but not a bucket lifecycle configuration, which is important for this project.
All of the code is on my Github.
Curator Backups: End-to-End Encryption
End-to-end encryption refers to any system that implements storage encryption-at-rest and network encryption-in-transit in all places. Curator achieves encryption-at-rest via Elastic’s repository-s3 plugin which encrypts snapshots and related files on EC2 storage before they are sent to S3. S3 has multiple encryption-at-rest options; this tut uses an Amazon S3 (IAM) bucket policy) because it encrypts everything in that enters the bucket by default, including metadata; the other options only encrypt S3 objects. Both the Elastic repository-s3 plugin, as well as the S3 bucket policy use AES256 as the encryption standard.
Encryption-in-transit between Curator, Elasticsearch and S3 is handled with TLS version 1.2 (still) as of 2018. Amazon is its own certificate authority and many applications include its root public key certificates in their corresponding certificate authority public key certificate “bundles” (ca bundles). If a master is transmitting to S3 then Curator handles TLS negotiation with the Python Certifi module’s ca bundle; if a data node needs to transmit to S3 then Curator hands this request to the repository-s3 plugin on that data node which then uses either openssl.cnf’s, or java’s, specified ca bundle. A basic diagram of the end-to-end encryption approach is below; click the image to enlarge it:
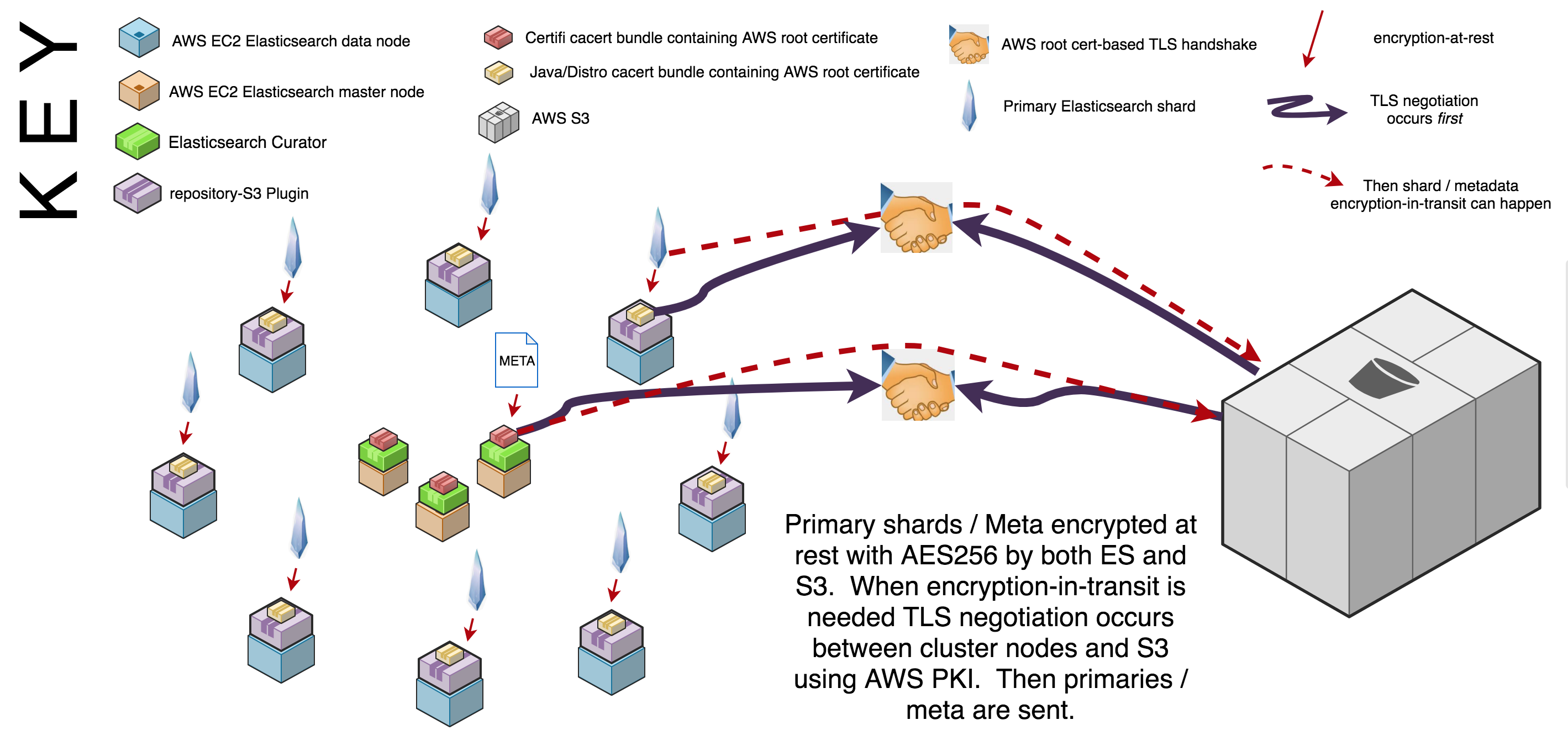
Curator Backups: Automation
The two most important parts of the encrypted backup process (as opposed to the backup monitoring/alerting process) are controlling which nodes receive Curator and automating repo and snapshot creation for your environments. Curator is only installed on the masters. Controlling Curator installation is done with the Puppet language e.g. if ::hostname =~ host.(dev|qa|prod).domain.com { include ::curator}, Puppet console or Hiera. For this project it is completed via Puppet Console. Automating repo and snapshot creation for your environments is handled with Puppet code. Controlling which nodes receive Curator is one of the most important features of this project because Curator runs as root and has the power to delete indices if configured to do so. While I realize that this article is about backing up Elasticsearch, as opposed to deleting it, it is still prudent to be defensive against anything that has the potential power to blow clusters away. Automating repo metadata naming conventions per your environments automates communication with AWS S3 which is the most crucial communication process required for this backup solution. The diagram below illustrates the approach just described; the diagram is followed by a more specific, step-by-step breakdown of the most important programmatic parts of the backup approach:

Automating Encrypted Curator Backups: Installing Elasticsearch’s repository-s3 Plugin
In order to use Curator to send and retrieve snapshots to and from s3, Elasticsearch requires that you install its repository-s3 plugin. The repository-s3 plugin, however, requires a full cluster restart if being installed in an already running cluster. Ideally, this plugin would be baked into an Elasticsearch image and therein a cluster restart would be avoided, but if, as was my case, you’re installing it after cluster initialization then you’ll want to plan for a cluster restart.
Check your cluster’s plugins like so:
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin list --verbose | grep s3
If the plugin is not installed the following block of Puppet code will deploy it for you:
exec {'repository-s3':
command => '/usr/share/elasticsearch/bin/elasticsearch-plugin install --batch repository-s3',
unless => "/bin/test -f ${::elasticsearch::params::plugindir}/repository-s3/plugin-descriptor.properties",
require => class[some_class_that_should_likely_come_before]
}
--batch mode forces Elasticsearch gain root in order to install the plugin. The unless attribute is a hack to check if the plugin is already installed, because Puppet and Elasticsearch will complain if is. Finally, the require block is for order dependency because of course Elasticsearch will need to be installed before the plugin install is attempted.
Automating Encrypted Curator Backups: Installing the Curator RPM
Installing Curator on CentOS 7 and with Puppet is a breeze. The code blocks below are so trivial I almost didn’t include them, but they do handle the case of an internally mirrored Elasticsearch yum repo, a chaining arrows dependency flow for ensuring that configuration files aren’t deployed until curator is installed and running Curator via cron:
yumrepo { 'curator':
enabled => $manage_repo,
baseurl => $baseurl
gpgcheck => 1,
gpgkey => $gpg_key_file_path
skip_if_unavailable => 0,
require => File[$gpg_key_file_ath]
} ~>
package { 'elasticsearch-curator':
ensure => present,
} ~>
file {'/opt/elasticsearch-curator/curator.yml':
ensure => file,
mode => '0640',
content => template("${module_name}/$path_to_curator.yml.erb"),
} ~>
file {'/opt/elasticsearch-curator/snapshot.yml':
ensure => file,
mode => '0640',
content => template("${module_name}/snapshot.yml.erb"),
} ->
file {'/etc/cron.d/snapshot_alert':
ensure => present,
mode => '0644',
content => "${snapshot_actions_cron_schedule} ${snapshot_actions_cron_user} /usr/bin/curator --config /opt/elasticsearch-curator/curator.yml /opt/elasticsearch-curator/snapshot.yml || /bin/bash /usr/local/bin/snapshot_alert.sh\n",
}
The yumrepo block configures a yum repo securely by forcing GPG key signature checking and since the elasticsearch-curator is signed by elasticsearch, using this feature is highly recommended. If you’re not mirroring the elasticsearch artifacts then this block isn’t needed.
I’m not a big fan of web templating, but if you’re not using Hiera, then you’ll definitely want to templatize your curator.yml and snapshot.yml configuration files for programmability and use the content => template(... attribute to deploy them via their respective file resources.
The ~> symbols are chaining arrows and are Puppet syntactic sugar for applying the resource on the left first and if that resource changes then refresh the resource on the right. The chaining arrows may be needed to ensure that the /opt/elasticsearch-curator/ dir, which is created by the installation of the elasticsearch-curator rpm, is present before any other files are associated with that directory, such as configuration files.
The -> syntax at the end of the dependency chain means apply the resource on the left, then the resource on the right, but do not refresh the resource on the right if the resource on the left changes. This ensures that the cron job is only populated if Curator is installed and assumes that a change to the snapshot.yml file doesn’t necessitate a change to the cron job.
The content attribute creates a short-circuit evalution between the Curator cron job and the snapshot_alert.sh script that attempts to execute Curator, but executes snapshot_alert.sh if Curator exits with anything but a code of 0. The snapshot_alert.sh will be covered in the alerting section.
Automating Encrypted Curator Backups: Creating an Encrypted Snapshot Repository
The code block below uses the Elasticsearch _snapshot API to create a repository in an elasticsearch cluster to store encrypted cluster snapshots that will be securely transmitted to, and possibly retrieved from, AWS S3. It’s a curl-based PUT using HTTP Basic Auth to authenticate an elasticsearch user to the cluster. In this PUT we send the required elasticsearch API values via curl’s -d switch, but we are also required to specify an HTTP header for this data being sent via -d that says its Content-Type is application/json which the elasticsearch API requires for reasons outlined in this post. The values assigned to the command’s json keys are all variables, with the exception of \"type\": \"s3\". The types and possible values for these variables can be reviewed here. The most important value is \"server_side_encryption\" which iencrypts via AES256 snapshots actualize end-to-end encryptionalmost without exceptionthough the two most important ones are ${_snapshot_repository} and "${_snapshot_bucket}\" because they automate the creation of repos according to host environment which is critical to the overall automation of this approach. Programmatically handling the assignment of these two values is discussed in the next two subsections. The \"server_side_encryption\" value is variablized, but must be set to true to actualize end-to-end encryptionalmost without exceptionFinally, the unless attribute is used because Puppet’s exec command is notorious for breaking idempotency as discussed in numerous places, including this post here.
exec { "create_${_snapshot_repository}_repo":
path => ['/bin', '/usr/bin' ],
unless => "curl -k -H 'Authorization: Basic ${::basic_auth_password}' https://$(hostname -f):9200/_cat/repositories | grep -q ${_snapshot_repository}",
command => "curl -k -XPUT -H 'Authorization: Basic ${::basic_auth_password}' https://$(hostname -f):9200/_snapshot/${_snapshot_repository} -H 'Content-Type: application/json' -d '{ \"type\": \"s3\", \"settings\": { \"bucket\": \"${_snapshot_bucket}\", \"compress\": \"${snapshot_bucket_compress}\", \"server_side_encryption\": \"${snapshot_bucket_server_side_encrypt}\", \"canned_acl\": \"${snapshot_bucket_canned_acl}\" } }'"
}
Automating Encrypted Curator Backups: Controlling for Elasticsearch repository name
This block automates assigning the $_snapshot_repository value required in the repo creation API call. In the case of a single cluster an if with an else case statement will do. The if clause covers overriding at the Puppet console or hiera level and the else case clause assigns a $_snapshot_repository value based on the domain of the host on which the Curator manifest is being executed.
if $snapshot_repository {
$_snapshot_repository = $snapshot_repository
} else {
case $facts['domain'] {
'dev.domain.com': { $_snapshot_repository = 'dev-snapshot-repo' }
'qa.domain.com': { $_snapshot_repository = 'qa-snapshot-repo' }
'prod.domain.com': { $_snapshot_repository = 'prod-snapshot-repo' }
default: { fail("domain must match \"^some message that covers all required domain cases$\"") }
}
}
If you have multiple cluster use cases then a more complex case statement leveraging regexing helps. The block below is a bit hard to read which is why declarative languages shouldn’t be used for scripting. Nonetheless it has been tested against environments with thousands of AWS EC2 instances and works just fine:
if $snapshot_repository {
$_snapshot_repository = $snapshot_repository
} else {
case $facts['hostname'] {
/^hostN.cluster.type.1.(dev|qa|prod).domain.com$/: { $_snapshot_repository = sprintf('%s-cluster-type-1-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
/^hostN.cluster.type.2.(dev|qa|prod).domain.com$/: { $_snapshot_repository = sprintf('%s-cluster-type-2-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
/^hostN.cluster.type.3.(dev|qa|prod).domain.com$/: { $_snapshot_repository = sprintf('%s-cluster-type-3-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
default: { fail("hostname must match \"^some message that covers all required hostname cases$\"") }
}
}
The number of repo names to create is the multiplicative product of the number of cluster types by the number of host environments, e.g. in the block above there are 3 cluster types cluster.type.1, cluster.type.2 and cluster.type.3 and 3 host environments (dev|qa|prod), hence the number of required repo names is 9, i.e dev-cluster-type-1-snapshot-repository, ..., prod-cluster-type-3-snapshot-repository. Puppet’s built-in function regsubst returns the host’s environment substring dev, qa, etc. to sprintf which in turn uses that value to interpolate its string formatted expression '%s-cluster-type-N-snapshot-repository', thereby assigning an environment to the cluster type, e.g. dev-cluster-type-1-snapshot-repository, ..., prod-cluster-type-3-snapshot-repository. The '\1' parameter of the regsubst function is a backreference to the first match between the capture group of (dev|qa|prod).domain.com and the ::domain value. For example, if ::domain == dev.domain.com, then in the case of host1.cluster.type.1.dev.domain.com regsubst would return dev; if ::domain == qa.domain.com then qa would be returned. The default case is to fail if a hostname match does not occur; keep in mind this will prevent puppet compilation meaning that the puppet code will not be executed at all, which provides added defense against creating a repo on a node that has somehow incorrectly entered the node group and has had Curator installed.
Automating Encrypted Curator Backups: Controlling for AWS S3 Bucket Name
The blocks below are identical to the ‘Controlling for Elasticsearch Repository Name’ blocks above, except in this case the S3 bucket name is being assigned:
# Single Cluster use case
if $bucket_name {
$_bucket_name = $bucket_name
} else {
case $facts['domain'] {
'dev.domain.com': { $_bucket_name = 'dev-s3-bucket' }
'qa.domain.com': { $_bucket_name = 'qa-s3-bucket' }
'prod.domain.com': { $_bucket_name = 'prod-s3-bucket' }
default: { fail("domain must match \"^some message that covers all required domain cases$\"") }
}
}
# Multiple cluster use cases
if $bucket_name {
$_bucket_name = $bucket_name
} else {
case $facts['hostname'] {
/^hostN.cluster.type.1.(dev|qa|prod).domain.com$/: { $_bucket_name = sprintf('%s-cluster-type-1-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
/^hostN.cluster.type.2.(dev|qa|prod).domain.com$/: { $_bucket_name = sprintf('%s-cluster-type-2-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
/^hostN.cluster.type.3.(dev|qa|prod).domain.com$/: { $_bucket_name = sprintf('%s-cluster-type-3-snapshot-repository', regsubst($::domain, '(dev|qa|prod).domain.com', '\1')) }
default: { fail("hostname must match \"^some message that covers all required hostname cases$\"") }
}
}
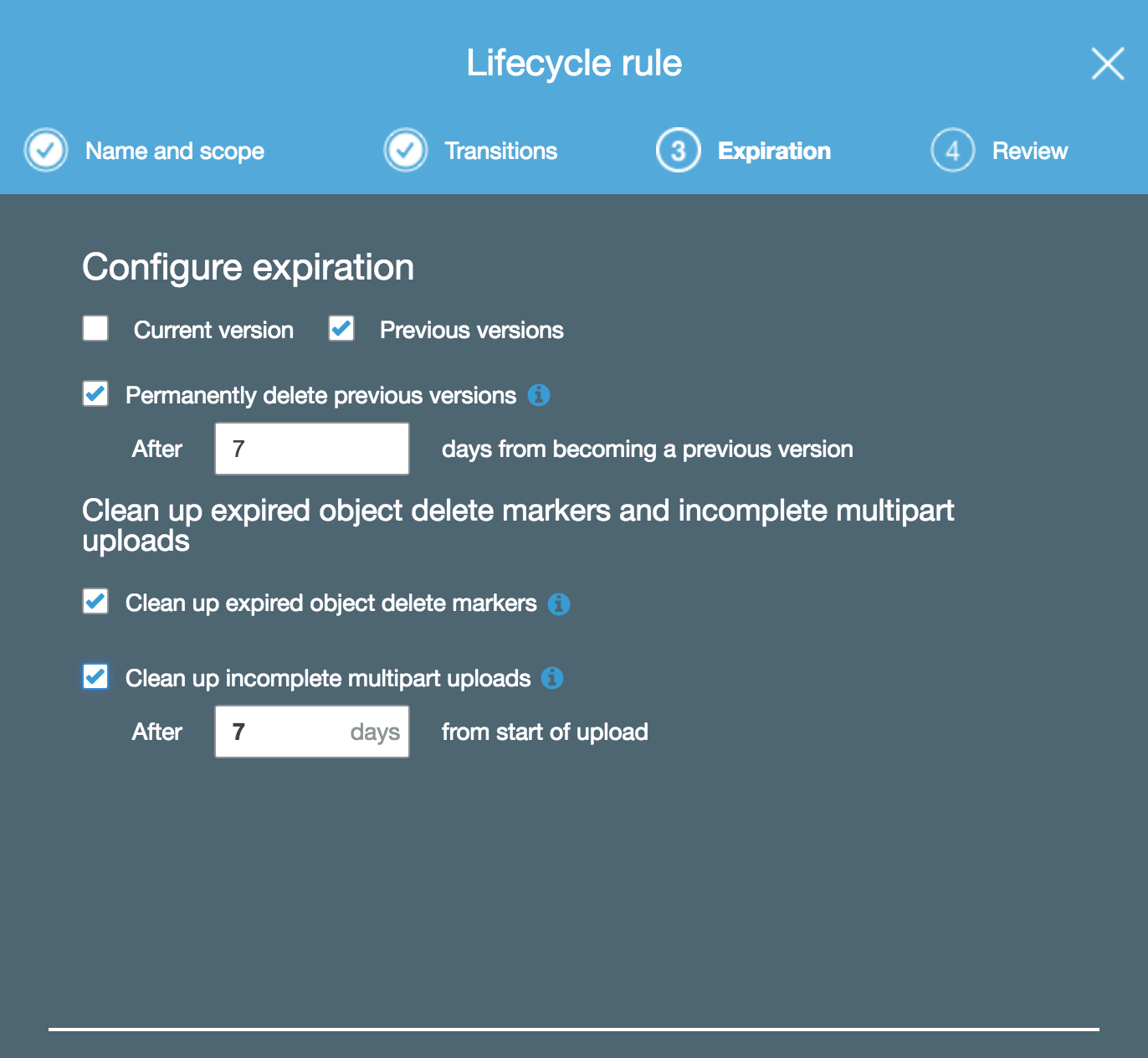
Automating Encrypted Curator Backups: Configuring Server-side Encryption and Snapshot cleanup in S3
Configuring complete Server-side encryption (SSE) for everything in an S3 bucket is so simple that I’m not going to explain it; just navigate to the Amazon S3 (IAM) bucket policy link posted above and change YourBucket to the name of the S3 bucket which will receive your cluster snapshots. Configuring snapshot cleanup is also trivial in S3 and is done using object lifecycle management. The image below shows a lifecycle rule set to delete any snapshot version or multipart upload that is older than a week, excluding the current snapshot version.
Puppet is now deploying and configuring Curator and the s3-repository plugin; the s3-repository plugin is encrypting cluster metadata at rest and is using the AWS root cert provided by the Java that Elasticsearch requires to send encrypted snapshots to an S3 bucket which has a bucket policy requiring encryption-in-transit and encryption-at-rest: end-to-end encrypted Curator backups have been achieved! Now we need to become aware of snapshot failures and alert when they happen. What follows is an approach to doing so using a patched version of rsyslog, some bash hacking and X-Pack Watcher. The Watcher code is: fairly untested; probably overkill; requires a paid Elasticsearch license. The crucial elements of monitoring and alerting your Curator backups is shipping Curator logs and centralizing those logs for later analysis, thus Watchers are not urgently, though they are a bit more modern than Bash in terms of alerting on elasticsearch.
Curator Backup Monitoring and Alerting
Curator generates a very useful log that reports whether or not snapshots succeed; shipping, centralizing and visualizing curator logs so that log data and metadata can be analyzed is critical to extrapolating and proving why snapshots are failing, e.g it may reveal that logs fail every Tuesday at 04:17:00PM PST / 12:17:00AM UTC which is right around when some bandwidth-hogging job completes. The shipping, centralizing and visualization tools used in this project are rsyslog, elasticsearch and kibana, respectively, because they are all FOSS and of course elasticsearch and kibana are a proximal leap from Curator, which already requires elasticsearch. Elasticsearch provides its own FOSS log shipper called filebeats, but I chose to use rsyslog because…in all honesty…Reddit said it was pointless despite Rsyslog being one of the most stable and mature shippers out. The precise approach is laid out in the diagram below (which does not enlarge):
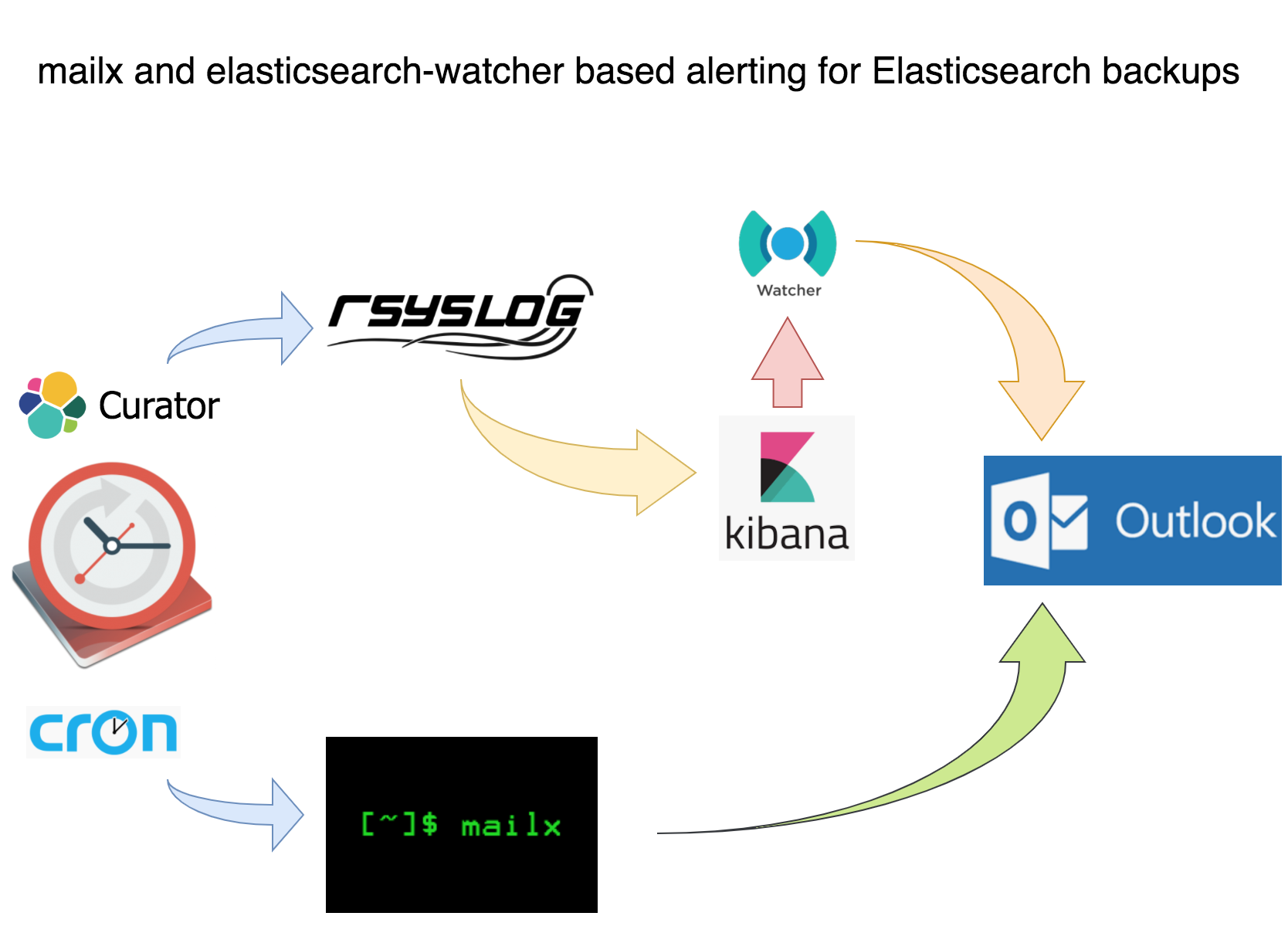
Curator Backup Monitoring and Alerting: Using Mailx for an Email Alert with Last Log Lines Attached
This tut assumes that you both postfix and mailx installed on your CentOS infrastructure because these are effectively the current basic standards for sending email on RHEL-variants. If you don’t you can follow DigitalOcean’s guide on doing so. The guide is for CentOS 6 and also configures Cyrus for SASL and IMAP, but it should get you started.
The content attribute of the snapshot_alert cron is a short-circuit statement the executes /usr/local/bin/snapshot_alert.sh if curator exits non-zero.
file {'/etc/cron.d/snapshot_alert':
ensure => present,
mode => '0644',
content => "${snapshot_actions_cron_schedule} ${snapshot_actions_cron_user} /usr/bin/curator --config /opt/elasticsearch-curator/curator.yml /opt/elasticsearch-curator/snapshot.yml || /bin/bash /usr/local/bin/snapshot_alert.sh\n",
}
Inside snapshot_alert.sh is a simple bash script that attaches the last 20 lines of the curator.log to an alert email.
#!/bin/bash
snapshot_alert() {
CLUSTER="$(SOME_CALL_TO_ES_API/_cluster/health | jq -r '.cluster_name')"
MAILTO=${MAILTO:-"your_alias@company.com"}
REPLYTO=${REPLYTO:-"${CLUSTER_NAME} <no-reply@company.com>"}
if [ -n "$REPLYTO" ] ; then
REPLYTO="-r $REPLYTO"
fi
SNAPSHOT_LOG="snapshot-alert-$(date +\%Y\%m\%d-\%s).log"
touch "$SNAPSHOT_LOG"
tail /var/log/elasticsearch-curator/curator.log | jq '.' > "$SNAPSHOT_LOG"
echo 'YOUR ALERT MESSAGE.' | mail -s "ALERT: Curator snapshot job exited with non-zero status" -a "$SNAPSHOT_LOG" "$REPLYTO" "$MAILTO"
exit 0
}
-s is the subject, -a is the log attachment and REPLYTO is the ‘from’ address. The expression date +\%Y\%m\%d-\%s is useful because it makes all log files unique by appending a typical datestamp with the Unix epoch seconds which is useful for analysis and also for shit-hitting-the-fan mode. This script, although only 15 lines or so, served as a great alert for my team. The attached log file is very convenient for a preview before logging into a visualizer like Kibana.
In case it isn’t obvious: this script needs to execute from your cluster masters because they are the only nodes that need Curator installed and will therefore be the only nodes to have curator logs.
Try executing Curator with broken credentials or something similar to test if your alert script and email infrastructure work. If they do you should see something similar to this:
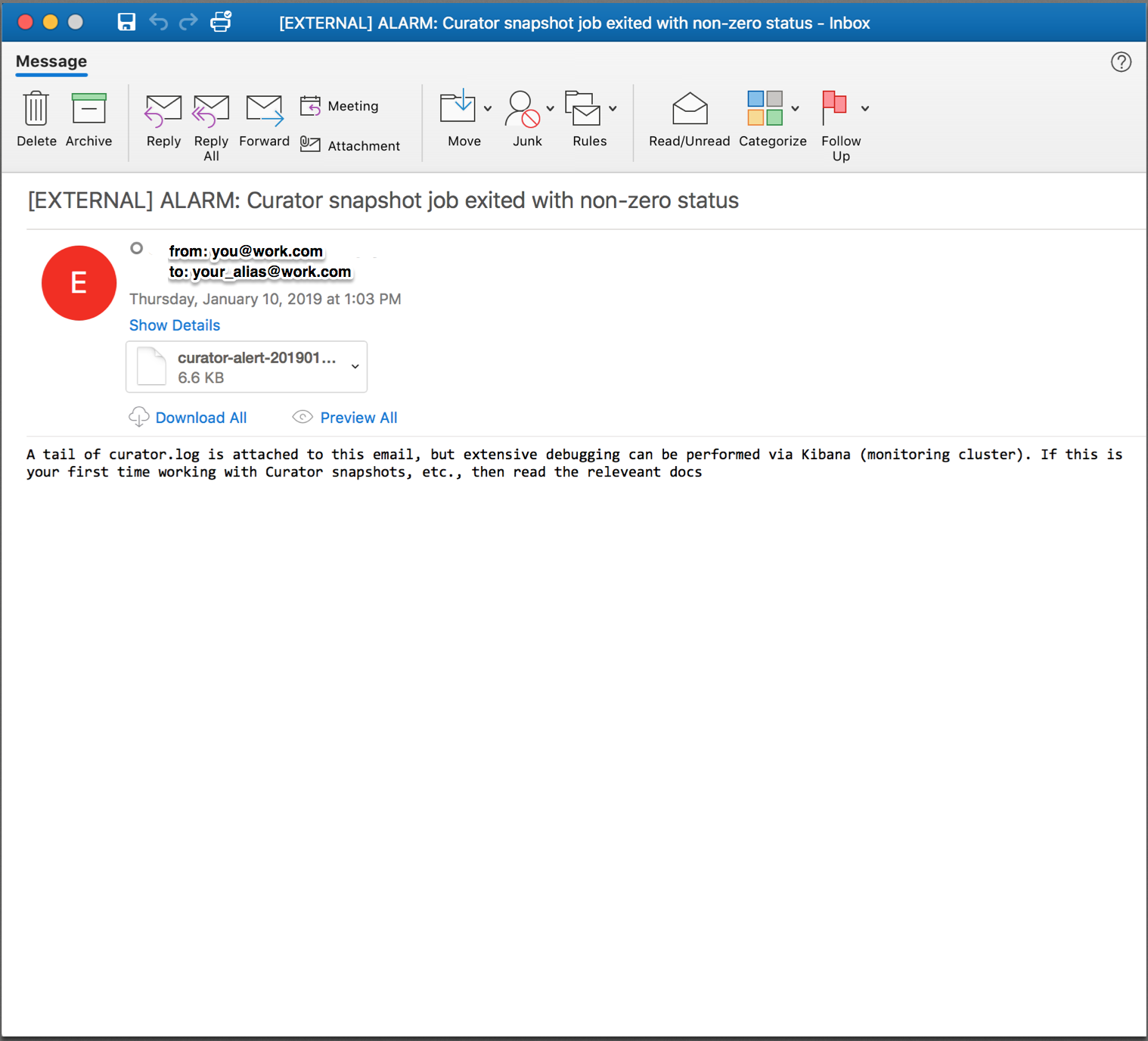
Which has a helpful log file attached so you can preview the errors and contemplate whether or not to possibly dig deeper:
A simple email alert with a log attached is a lot better than nothing, but centralizing curator logs with elasticsearch and visualizing them with Kibana allows me to parse and search multiple logs from multiple machines and environments all from the same UI and when snapshots are failing for unknown reasons, which I discuss later on, this can prove crucial to resolving the failures, which is crucial to having confidence in your elasticsearch cluster. If you’re not going to use a visualizer like Kibana then this is effectively the end of the tut for you. Otherwise:
Curator Backups Monitoring and Alerting: Shipping via a Patched Rsyslog
Elasticsearch 6 implemented strict content-type checking for clarity and security, which is great, except Rsyslog’s omelasticsearch module still uses text/json as its content type which is not allowed; instead application/json must be used. This one word is a full breaker! This will not be fixed until at least RHEL 8 which you can read about in this bugzilla report. Nonetheless, as supporters of FOSS we must stay calm and patch on!
# first we need to wget the source rpm
# adjust the repository link as needed
jonas@devbox ~ $ wget http://vault.centos.org/7.5.1804/os/Source/SPackages/rsyslog-8.24.0-16.el7.src.rpm
--2019-03-30 09:10:51-- http://vault.centos.org/7.5.1804/os/Source/SPackages/rsyslog-8.24.0-16.el7.src.rpm
Resolving vault.centos.org (vault.centos.org)... 208.100.23.71, 2607:f128:40:1600:225:90ff:fe00:bde6
Connecting to vault.centos.org (vault.centos.org)|208.100.23.71|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 6778207 (6.5M) [application/x-rpm]
Saving to: ‘rsyslog-8.24.0-16.el7.src.rpm.1’
100%[========================================================================================>] 6,778,207 37.6KB/s in 9.1s
Now we need to setup an RPM building environment
# get needed packages
# you're going to need gcc, autotools, etc
# feel free to remove all this afterwards
sudo yum groupinstall 'Development Tools'
# rpm-build packages is
# actually called 'rpmbuild'
# when executing from command line
# we need yum-utils (at least) for
# building deps later
sudo yum install yum-utils rpm-build redhat-rpm-config
# now we need to install build dependencies
# require by the rsyslog source RPM
# this installs a number of packages because
# rsyslog builds all of its modules into
# a single RPM
sudo yum-builddep rsyslog-8.24.0-34.el7.x86_64
# make sure rsyslog isn't currently installed
# because we need to install from source which
# will give us access to the rsyslog rpm spec
# and patch files
sudo yum remove rsyslog
# create dir structure
mkdir -p ~/rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS}
# set the _topdir var for rpmbuild
# this needs to point at the rpmbuild directory
# from the mkdir command above
# as rpmbuild will use this to traverse into the
# various rpm-related directories
echo '%_topdir %(echo $HOME)/rpmbuild' > ~/.rpmmacros
# install via the source rpm
rpm -i rsyslog-8.24.0-16.el7.src.rpm
If everything has gone well then you should have an RPM build environment with the rsyslog-8.24.0-16.el7.src.rpm source files structured as below:
jonas@devbox ~ $ ls -R rpmbuild/SOURCES
.:
BUILD RPMS rsyslog-8.24.0-16.el7.src.rpm SOURCES SPECS SRPMS
./BUILD:
./RPMS:
./SOURCES:
rsyslog-8.24.0-doc-polling-by-default.patch rsyslog-8.24.0-rhbz1427821-backport-num2ipv4.patch
rsyslog-8.24.0-msg_c_nonoverwrite_merge.patch rsyslog-8.24.0-rhbz1427821-str2num-emty-string-handle.patch
rsyslog-8.24.0-rhbz1056548-getaddrinfo.patch rsyslog-8.24.0-rhbz1427828-set-unset-not-checking-varName.patch
rsyslog-8.24.0-rhbz1088021-systemd-time-backwards.patch rsyslog-8.24.0-rhbz1431616-pmrfc3164sd-backport.patch
rsyslog-8.24.0-rhbz1165236-snmp-mib.patch rsyslog-8.24.0-rhbz1459896-queues-defaults-doc.patch
rsyslog-8.24.0-rhbz1196230-ratelimit-add-source.patch rsyslog-8.24.0-rhbz1462160-set.statement-crash.patch
rsyslog-8.24.0-rhbz1245194-imjournal-ste-file.patch rsyslog-8.24.0-rhbz1488186-fixed-nullptr-check.patch
rsyslog-8.24.0-rhbz1303617-imfile-wildcards.patch rsyslog-8.24.0-rhbz1497985-journal-reloaded-message.patch
rsyslog-8.24.0-rhbz1399569-flushontxend.patch rsyslog-8.24.0-rhbz1505103-omrelp-rebindinterval.patch
rsyslog-8.24.0-rhbz1400594-tls-config.patch rsyslog-8.24.0-rhbz1507028-recover_qi-doc.patch
rsyslog-8.24.0-rhbz1401456-sd-service-network.patch rsyslog-8.24.0-sd-service.patch
rsyslog-8.24.0-rhbz1401870-watermark.patch rsyslog-8.24.0.tar.gz
rsyslog-8.24.0-rhbz1403831-missing-cmd-line-switches.patch rsyslog.conf
rsyslog-8.24.0-rhbz1403907-imudp-deprecated-parameter.patch rsyslog-doc-8.24.0.tar.gz
rsyslog-8.24.0-rhbz1419228-journal-switch-persistent.patch rsyslog.log
rsyslog-8.24.0-rhbz1422414-glbDoneLoadCnf-segfault.patch rsyslog.sysconfig
rsyslog-8.24.0-rhbz1422789-missing-chdir-w-chroot.patch
./SPECS:
rsyslog.spec
./SRPMS:
untar rsyslog-8.24.0.tar.gz because the file we need to patch is inside it:
jonas@devbox ~ $ tar -vzxf rpmbuild/SOURCES/rsyslog-8.24.0.tar.gz -C rpmbuild/SOURCES/
Now we need patch files that will make rsyslog use strict Content-Type checking. The first file rsyslog-8.24.0-rhbz1600171-omelasticsearch-strict-content-type-for-es.patch goes in the ~/rpmbuild/SOURCES dir; the second file spec.patch can go in $HOME. The md5sums of these files are bb63628eb31625708b2bfa and a0e7fa26cf71bf55fff37b54649a7041, respectively. However you get the to your local box or server, make sure these md5sums stay the same because introducing any changes into them will most likely break the RPM build: I am speaking from painful personal experience!
rsyslog-8.24.0-rhbz1600171-omelasticsearch-strict-content-type-for-es.patch
Inside spec.patch edit line 32 if you wish and enter the current date and an email; IMPORTANT: use the exact format that is currently being used or the RPM will not build. Also, on lines 7 and 8 is:
-Release: 16%{?dist}
+Release: 16%{?dist}.1
The .1 is accounting for the logically resultant minor version bump post-RPM build. There is actually a fair amount of thought given to RPM versioning and you can read about Fedora’s here.
Now we need to patch the rsyslog rsyslog.spec file with the spec.patch file:
patch -i spec.patch rpmbuild/SPECS/rsyslog.spec
Now build the RPM:
# this takes a minute or two
rpmbuild -ba rpmbuild/SPECS/rsyslog.spec
After the rpmbuild finishes you’ll have a source RPM:
jonas@devbox ~ $ ls rpmbuild/SRPMS/
rsyslog-8.24.0-16.el7.1.src.rpm
and the entire rsyslog artifact RPM catalog:
jonas@devbox ~ $ ls rpmbuild/RPMS/x86_64/
rsyslog-8.24.0-16.el7.1.x86_64.rpm rsyslog-mmjsonparse-8.24.0-16.el7.1.x86_64.rpm
rsyslog-crypto-8.24.0-16.el7.1.x86_64.rpm rsyslog-mmnormalize-8.24.0-16.el7.1.x86_64.rpm
rsyslog-debuginfo-8.24.0-16.el7.1.x86_64.rpm rsyslog-mmsnmptrapd-8.24.0-16.el7.1.x86_64.rpm
rsyslog-elasticsearch-8.24.0-16.el7.1.x86_64.rpm rsyslog-mysql-8.24.0-16.el7.1.x86_64.rpm
rsyslog-gnutls-8.24.0-16.el7.1.x86_64.rpm rsyslog-pgsql-8.24.0-16.el7.1.x86_64.rpm
rsyslog-gssapi-8.24.0-16.el7.1.x86_64.rpm rsyslog-relp-8.24.0-16.el7.1.x86_64.rpm
rsyslog-libdbi-8.24.0-16.el7.1.x86_64.rpm rsyslog-snmp-8.24.0-16.el7.1.x86_64.rpm
rsyslog-mmaudit-8.24.0-16.el7.1.x86_64.rpm rsyslog-udpspoof-8.24.0-16.el7.1.x86_64.rpm
You can use all of these minor-bumped RPMs or only rsyslog-8.24.0-16.el7.1.x86_64.rpm. Whatever the case we will be using the rsyslog-related RPMs below for massing curator logs into a json-like format that elasticsearch can ingest, as well as handling TLS.
rsyslog-mmjsonparse-8.24.0-16.el7.some_version.x86_64
rsyslog-8.24.0-16.el7.1.x86_64
rsyslog-elasticsearch-8.24.0-16.el7.some_version.x86_64
rsyslog-gnutls-8.24.0-16.el7.some_version.x86_64
rsyslog-relp-8.24.0-16.el7.some_version.x86_64
Pro-tip: use yum versionlock to prevent configuration management and therein yum from installing a non-patched version of rsyslog-8.24.0-16.el7*.x86_64.rpm; you can read about how to do that at Redhat.
Now that we have patched rsyslog we can use it to ship Curator logs to elasticsearch, but first we need to deploy and configure rsyslog to do so.
Curator Backup Monitoring and Alerting: Deploying and versionlocking Rsyslog with Puppet
This section may not fully apply to your team because maybe you’re not using Puppet to deploy and configure Rsyslog. Even if you’re not, be mindful of other applications (Chef, CFEngine, whatever) removing your patched rsyslog RPM for another one. One way to deal with this is to use yum versionlock. The manifest below deploys Rsyslog and prevents anything from removing it. It’s not the prettiest, but it works. Remove values like $curator_elb if needed. Regarding TLS this is another very convenient case for assigning $curator_cacert to a Puppet master’s root cert and $curator_cert and $curator_key to the same Puppet master’s client-side x.509 certificate and private key. We assign these last to values to the master because Curator is running on the master, whereas normally the client values would refer to a typical puppet agent’s cert and private key.
# @author Jonas M. Steinberg <jonassteinberg1@gmail.com>
class profile::rsyslog (
$curator_log_file = '/var/log/elasticsearch-curator/curator.log',
$curator_elb = undef,
$curator_elb_port = '9200',
$curator_cacert = undef,
$curator_cert = undef,
$curator_key = undef,
$curator_username = undef,
$curator_password = undef,
$curator_bulkmode = 'on',
$curator_batchsize = '500',
$curator_queuesize = '10000',
$curator_threads = '2',
$curator_retries = '-1',
$curator_rsyslog_rpm_version = '8.24.0-16.el7.1.x86_64',
){
if $::fqdn =~ /^$your_domain_convention/ {
$packages = ["rsyslog-mmjsonparse-${curator_rsyslog_rpm_version}", "rsyslog-elasticsearch-${curator_rsyslog_rpm_version}"]
file { '/etc/rsyslog.d/11-curator-elasticsearch.conf':
ensure => present,
content => template("${module_name}/11-curator-elasticsearch.conf.erb"),
}
package { 'yum-plugin-versionlock':
ensure => 'latest',
} ~> exec { "yum versionlock rsyslog-*${curator_rsyslog_rpm_version}":
path => ['/usr/bin/', '/sbin/'],
} ~> package { 'rsyslog-8.24.0-16.el7_5.4':
ensure => absent
} ~> package { $packages:
ensure => 'latest',
}
}
The $packages line installs the mmjsonparse and elasticsearch rsyslog module RPMs, which triggers the install of the gnutls and relp module RPMS, all of which are needed to handle fully-duplexed TLS connections from curator to elasticsearch. If you’re not using Puppet to deploy and configure rsyslog make sure to install these other packages.
Curator Backup Monitoring and Alerting: Templatizing Rsyslog’s Configuration file
Rsyslog is part of any RHEL-variant and this tut’s additional configuration below should work with any RHEL-variant’s base rsyslog.conf file. If for some reason your rsyslog.conf is not a base install then I assume that you or someone on your team has some experience with rsyslog and will be able to make any changes necessary. Similarly, if you change or remove anything but the ERB variables themselves, or code related to those variables, in the template below then good luck to you: the rsyslog documentation is pretty extensive, but not 100% clear.
The configuration grabs every event and every piece of every event’s metadata; in other words it ships everything in the curator logs to elasticsearch. This is a time series process that creates indices in the curator-YYYY-MM-DD format and rsyslog is smart enough to know when a date change has occurred. I recommend telling Curator to purge logs older than a certain date which can be read about here and here. As for the rsyslog configuration itself I list two excellently related sources in the comments.
This file should almost certainly be in the /etc/rsyslog.d dir.
# @author Jonas Steinberg <jonassteinberg1@gmail.com>
# source: https://serverascode.com/2016/11/11/ryslog-to-elasticsearch.html
# source: https://techpunch.co.uk/development/how-to-shop-json-logs-via-rsyslog
# pro-tip: order of directives such as templates and ruleset
# that call template (and likely other directives) matters
# in rsyslog.
module(load="omelasticsearch")
module(load="mmjsonparse")
module(load="imfile")
# ingest the curator file
input(type="imfile"
File="<%= @curator_log_file %>"
Tag="curator-events"
addMetadata="on"
ruleset="curatorToElasticsearchRuleset"
)
# template to generate JSON documents for Elasticsearch in curator format
template(name="curatorLogTemplate"
type="list") {
constant(value="{ ")
constant(value="\"type\":\"")
property(name="programname")
constant(value="\", ")
constant(value="\"host\":\"")
property(name="hostname")
constant(value="\", ")
constant(value="\"sourcefile\":\"")
property(name="$!metadata!filename")
constant(value="\", ")
property(name="$!all-json" position.from="2")
}
# formats index names as curator-YYYY-MM-DD
template(name="curator-index"
type="list") {
constant(value="curator-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}
ruleset(name="curatorToElasticsearchRuleset") {
action(type="mmjsonparse" cookie="")
action(type="omelasticsearch"
server="<%= @curator_elb %>"
serverport="<%= @curator_elb_port %>"
usehttps="on"
tls.cacert="<%= @curator_cacert %>"
tls.mycert="<%= @curator_cert %>"
tls.myprivkey="<%= @curator_key %>"
uid="<%= @curator_username %>"
pwd="<%= @curator_password %>"
template="curatorLogTemplate"
searchIndex="curator-index"
dynSearchIndex="on"
searchType="events"
bulkmode="<%= @curator_bulkmode %>" # use the Bulk API
queue.dequeuebatchsize="<%= @curator_batchsize %>" # ES bulk size
queue.size="<%= @curator_queuesize %>" # capacity of the action queue
queue.workerthreads="<%= @curator_threads %>" # num of workers for the action
action.resumeretrycount="<%= @curator_retries %>" # retry indefinitely if ES is unreachable
errorfile="/var/log/rsyslog-curator-error.log"
)
stop
}
# debugging
$DebugFile /var/log/rsyslog-debug.log
$DebugLevel 2
The config writes debug to /var/log/rsyslog-debug.log at debug level 2 which is full debug; 0 is off and 1 is ‘demand activity’. Read about rsyslog debugging here. Another very helpful rsyslog debug command is:
rsyslogd -N1
Tailing /var/log/rsyslog-debug.log should be quite insightful as to whether or not rsyslog is able to ship to elasticsearch. For example, if the log file you’re attempting to ingest doesn’t exist you might see something like:
2924.419291019:main Q:Reg/w0 : main Q:Reg/w0: worker IDLE, waiting for work.
2934.405625872:imfile.c : file '/var/log/elasticsearch-curator/curator.lo' opened as #-1 with mode 384
2934.405660661:imfile.c : strm 0x7f95f40020c0: open error 2, file '/var/log/elasticsearch-curator/curator.lo': No such file or directory
2944.415070349:imfile.c : file '/var/log/elasticsearch-curator/curator.lo' opened as #-1 with mode 384
2944.415098226:imfile.c : strm 0x7f95f40020c0: open error 2, file '/var/log/elasticsearch-curator/curator.lo': No such file or directory
With some squinting rsyslog-debug.log will also show when everything is working:
6381.089160417:main Q:Reg/w0 : processBATCH: next msg 4: {"@timestamp": "2019-03-01T23:52:59.719Z", "function": "log_request_success", "linenum": 86, "loglevel": "DEBUG", "message": "<
6381.089163406:main Q:Reg/w0 : ACTION 0 [mmjsonparse:action(type="mmjsonparse" ...)]
6381.089170492:main Q:Reg/w0 : executing action 0
6381.089173876:main Q:Reg/w0 : action 'action 0': called, logging to mmjsonparse (susp 0/0, direct q 1)
6381.089177318:main Q:Reg/w0 : Action 0 transitioned to state: itx
6381.089194969:main Q:Reg/w0 : entering actionCalldoAction(), state: itx, actionNbr 0
6381.089206267:main Q:Reg/w0 : mmjsonparse: toParse: '{"@timestamp": "2019-03-01T23:52:59.719Z", "function": "log_request_success", "linenum": 86, "loglevel": "DEBUG", "message": "< {\"snapshots\":[{\"snapshot\":\"domain.com-20190301235236\"
...
6381.089379956:main Q:Reg/w0 : Action 0 transitioned to state: rdy
6381.089390462:main Q:Reg/w0 : action 'action 0': set suspended state to 0
6381.089393718:main Q:Reg/w0 : ACTION 1 [omelasticsearch:action(type="omelasticsearch" ...)]
6381.089406465:main Q:Reg/w0 : executing action 1
6381.089414707:main Q:Reg/w0 : action 'action 1': called, logging to omelasticsearch (susp 0/0, direct q 1)
6381.089483784:main Q:Reg/w0 : action 'action 1': is transactional - executing in commit phase
...
6901.565868820:main Q:Reg/w0 : omelasticsearch: checkConn(https://es_cluster:9200/) completed with success on attempt 0
6901.565900813:main Q:Reg/w0 : omelasticsearch: using REST URL: 'https://es_cluster:9200/_bulk'
6901.573745733:main Q:Reg/w0 : omelasticsearch: pWrkrData replyLen = '3656'
6901.573771695:main Q:Reg/w0 : omelasticsearch: pWrkrData reply: '{"took":4,"errors":false,"items":[{"index":{"_index":"curator-2019.03.01"
When the debug log looks healthy try cat’ing the curator indices on your cluster:
jonas@es_cluster ~ $ sudo curl -skn https://$(hostname -f):9200/_cat/indices?v | awk '{ print $3 }' | sort -n
curator-2019.02.26
curator-2019.02.27
curator-2019.02.28
curator-2019.03.01
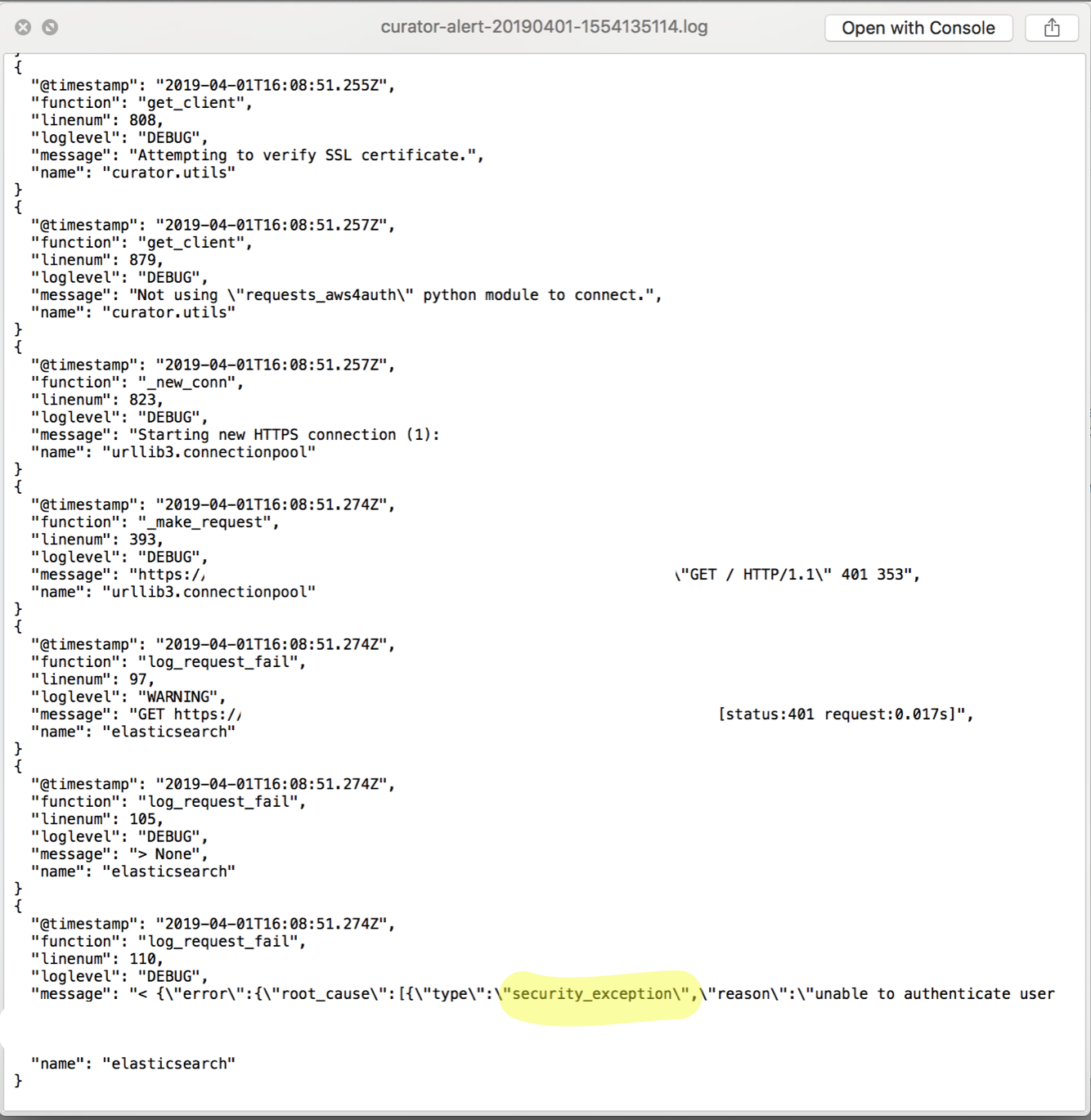
The attached log file above reported that Curator failed with a security_exception. Click the image below to enlarge the screenshot of the Kibana ‘discovery’ UI.
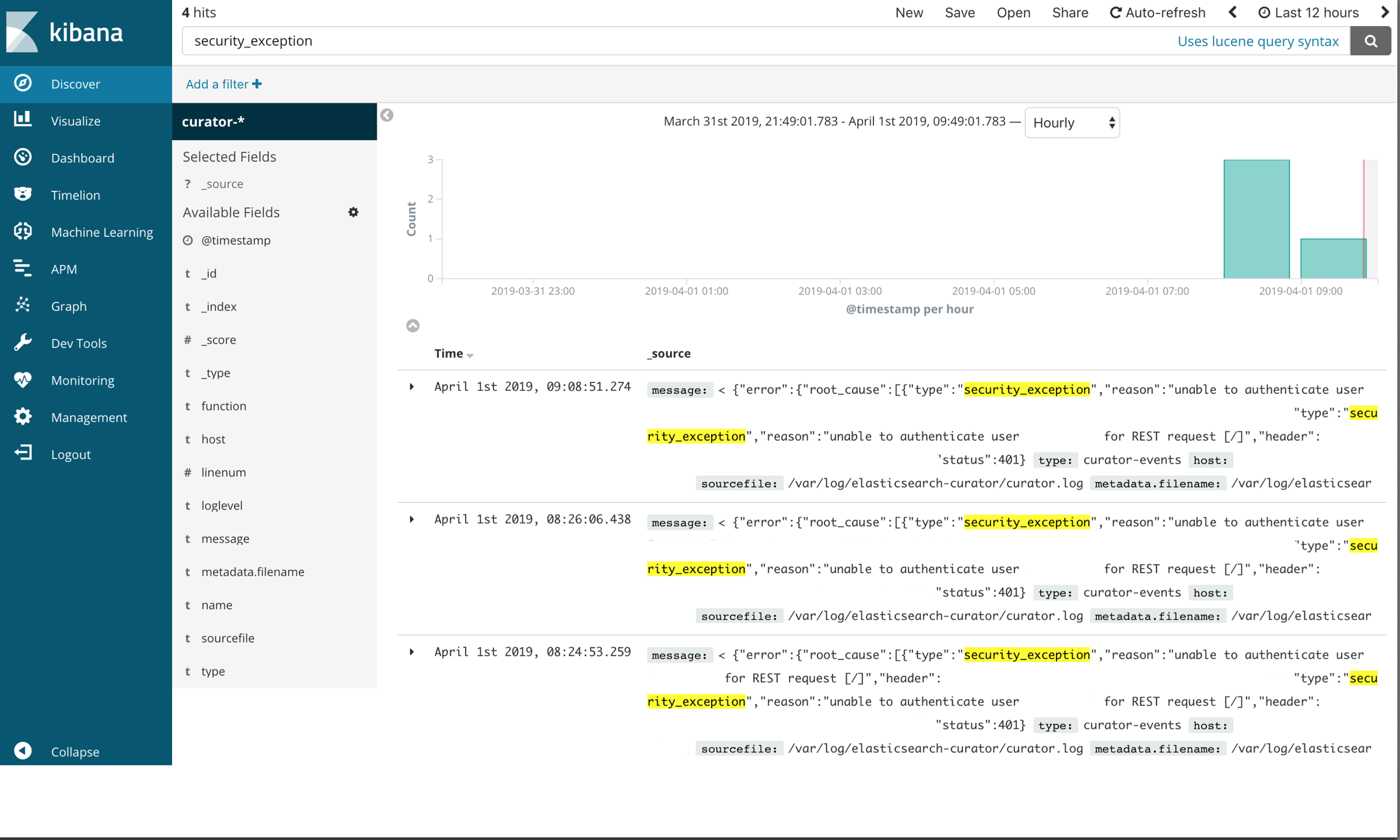
The ‘security_exception’ example isn’t a great one to demonstrate the necessity of Kibana analysis because it’s a trivial error to solve: it says right in the error unable to authenticate user [user], but there are more complex failure scenarios in which a visualizer like Kibana is very helpful. Unfortunately I don’t have a nice Kibana example of this because it has been solved within my systems and those elasticsearch events have long been purged, but I do have logs. Imagine something like this:
{
"@timestamp": "2019-01-10T21:02:15.048Z",
"function": "snapshot_check",
"linenum": 1553,
"loglevel": "WARNING",
"message": "Snapshot my-aws-s3-20190110210002 completed with state PARTIAL.",
"name": "curator.utils"
}
{
... # whole lot of metadata
... # relevant bit
"IndexShardSnapshotFailedException[error deleting index file [pending-index-3] during cleanup]; nested: NoSuchFileException[Blob [pending-index-3] does not exist]; \",\"node_id\":\"some_node_id\",\"status\":\"INTERNAL_SERVER_ERROR\"}],\"shards\":{\"total\":395,\"failed\":2,\"successful\":393}}]}",
}
{
"@timestamp": "2019-01-10T21:02:15.105Z",
"function": "report_state",
"linenum": 1498,
"loglevel": "ERROR",
"message": "Snapshot PARTIAL completed with state: PARTIAL",
"name": "curator.actions.snapshot"
}
{
"@timestamp": "2019-01-10T21:02:15.105Z",
"function": "run",
"linenum": 186,
"loglevel": "ERROR",
"message": "Failed to complete action: snapshot. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: Snapshot PARTIAL completed with state: PARTIAL",
"name": "curator.cli"
}
In the end NoSuchFileException[Blob [pending-index-3] does not exist] was caused by a curator delete index action job that was breaking my snapshot action: the snapshot was kicking off first and then the delete index action would run and snapshot wouldn’t be able to find an index that its metadata said should be there. With multiple environments and deployments of elasticsearch all running curator and all failing with this same error a log attached to an email wasn’t effective and Kibana analysis gave me the visual insight I needed to resolve the snapshot failures by mapping IndexShardSnapshotFailedException times with machines in multiple environments.
Curator Backup Monitoring and Alerting Bonus Section: An X-Pack Watcher Example that Triggers when “Security Exception … Unable to Authenticate User” Condition is Met
Because X-Pack Watchers are native to elasticsearch it means that you can stop managing alert scripts through your data clusters and although the programmatic capabilities of them aren’t more expansive than Bash, let’s be honest: writing alert scripts in Bash is probably a bit of a legacy approach at this point; if you have a paid elasticsearch license, I highly recommend using them. Watchers are a big topic and only a simple example of triggering off of the security_exception from above is covered, but the Watchers documentation is very good and this should be enough to get you started.
Watchers are scripts written json that are installed to elasticsearch via the _xpack/watcher API. There are five basic sections to a watch: trigger’s specify the when to run the alert, we’re using a minute interval; inputs’s load data that the watch is going to execute, we’re using a search input which is a query against our curator-YYYY.MM.DD indices; condition’s determine whether or not to execute the watch, we’re going to trigger if there are any security_exceptions; action’s specify alert type, e.g. jira, slack or in our case email; transform’s modify how the watch payload is processed by the action, they’re not used in this example, but transforms can be a script that operates on a search query and extracts only needed information, thereby reducing payload size.
I highly recommend using the Kibana Dev Tools section to PUT your watchers; this is one case where a web frontend outdoes curl:

The watcher example code is too long to capture a watcher install from the Kibana dev tools UI in a screenshot, but all that needs to be done is access Kibana, select dev tools, copy-and-paste the code, update the values to match your system and press the play button. Debugging is also a lot easier in the dev tools UI as opposed to accessing the watchers indices directly via curl:
{
"trigger": {
"schedule": {
"hourly": {
"minute": [
59
]
}
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": [
"<curator-{now/d{YYYY.MM.dd}}>"
],
"types": [],
"body": {
"size": 20,
"query": {
"bool": {
"must": {
"query_string": {
"query": "message : security_exception unable to authenticate user",
"analyze_wildcard": true,
"default_field": "*"
}
},
"filter": [
{
"range": {
"@timestamp": {
"gte": "now-1h"
}
}
}
]
}
}
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gt": 0
}
}
},
"actions": {
"send_email_notification": {
"throttle_period_in_millis": 14400000,
"email": {
"profile": "standard",
"attachments": {
"data.yml": {
"data": {
"format": "yaml"
}
}
},
"priority": "high",
"to": [
"jsteinberg@mmm.com"
],
"subject": "{{ctx.metadata.email_subject}}",
"body": {
"html": "<!DOCTYPE html><html><body><h2>{{ctx.metadata.email_body_header}}<p>Security Exception Received Monitoring Cluster from DI -- {{ctx.payload.hits.total}} Events Received </h2><small><p>Executed watch [{{ctx.watch_id}}] at [{{ctx.execution_time}}].<p>Do not reply to this email. The sending account is not monitored.</small></body></html>"
}
}
}
},
"metadata": {
"email_body_header": "Monitoring Cluster Security Exception Alert - DI Environment",
"email_subject": "Monitoring Cluster Security Exception Alert - DI Environment"
}
}
The trigger section specifies that this watcher will execute on the 59th minute of every hour. The input is of type search which supports the full elasticsearch query DSL; in other words it’s a _search API request. Basically this section says for the last 4 hours search every document on every index like curator-YYYY.MM.DD for a substring of message : security_exception unable to authenticate user. To understand exactly what’s going on in this part of the watcher you can read the following documentation:
The condition section specifies that our query matches anything we want to be alerted. The action section specifies whom to alert, handles some basic web templating and attaches matching records to the email in a yaml file. The option metadata section lends logic to our action section.
After installing your updated watcher via the dev tools UI you can force an execution of it by going to the Watcher section in the Management UI. From there search for your watcher by name, click on the watcher link and select the Edit tab at the top of the page. On the Edit page select the Simluate tab. From there select a Condition Override of Ignore Condition and a Action Override of force execution.
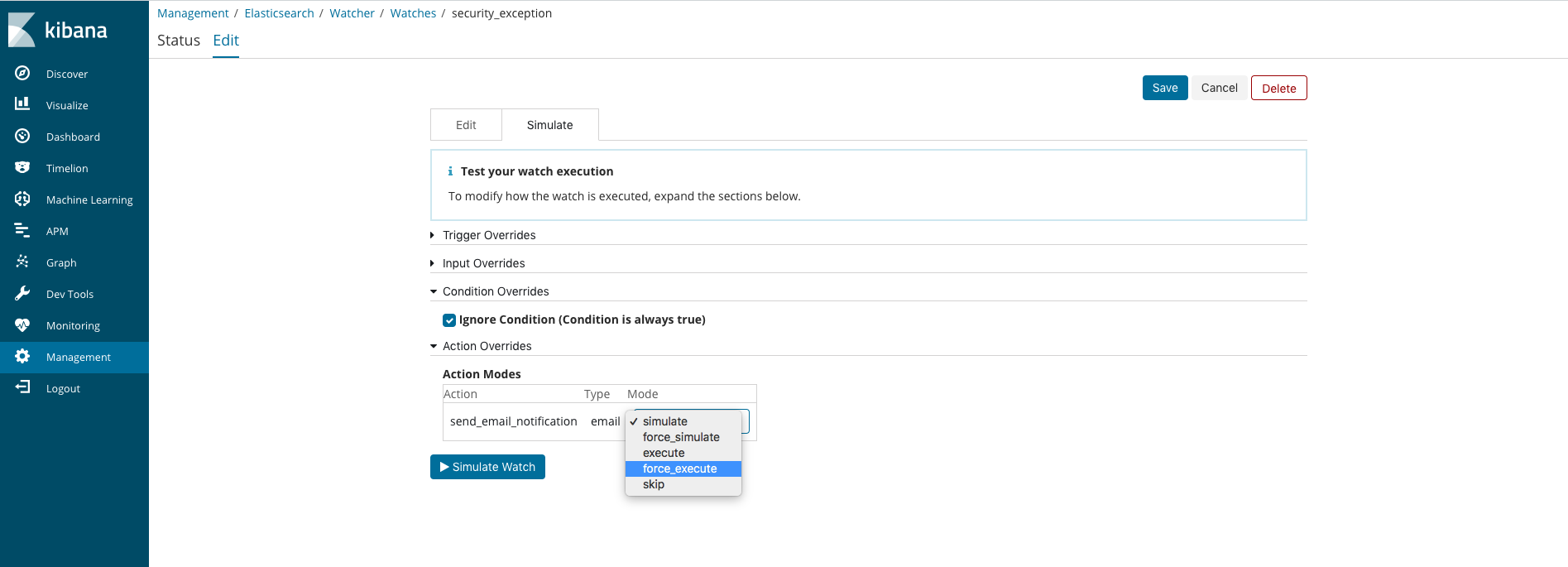
If you receive an email alert like the one below then you know your watcher is installed and working:
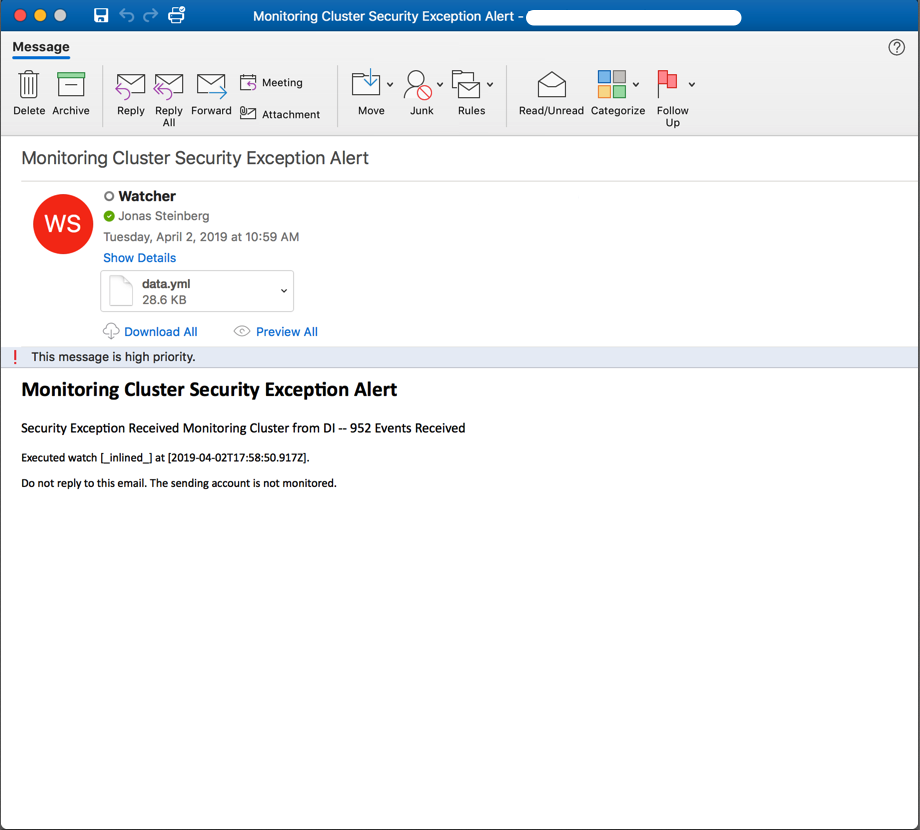
If a yaml file of matching records is attached then your query produced matches; if not then uncheck the Ignore Condition override and play with your query substring until you are receiving matched records containing data of some utility:
Pro-Tips for Having Confidence in Your Curator Backups
Backing up elasticsearch with Curator doesn’t mean anything if you cannot actually restore your clusters. Doing a full restore on a massive production cluster will be time consuming and potentially expensive, but do yourself a favor and prove that you can deploy new cluster server infrastructure, including load balancers, PKI, etc. and then use Curator or Elasticsearch to do a full restore in at least Dev and QA. Given a massive cluster outage there could be nothing worse then having to explain why the backup solution isn’t working.
Finally, when automating Curator make sure that whatever programmatic logic you use it handles putting the right curator jobs on the right machines. For example, if some machines also have Curator delete indices being run on them, make sure that those jobs don’t end up on clusters that should never have indices deleted.
Conclusion
Many teams have legacy Puppet deployments and large Elasticsearch clusters with data that should probably be backed up. The solution provided above works and was tested at massive scale. Although patching Rsyslog is kludgy, there is something nice about not needing to add another package across your infrastructure, even if elastic’s Filebeats is free and easy to use. If you’ve skimmed through this and it seems relevant go to my github and look at the code; if you’re in the middle of something similar and want advice feel free to email or tweet because I’d be happy to lend a set of ears and impart any knowledge I have that may be relevant.
- watcher…
conclusion
pro-tips
- go through a whole restore
- don’t delete everything with curator jobs